Attribute Buckets in DataVault
Introduction
SlashID Data Vault provides secure storage for any information associated with a user. User data is represented and stored as key-value pairs, which can be retrieved and used at any point in time. However, not all user data is equal, and you may often want to control who is able to access and modify specific data. By defining permissions at the bucket level, you can easily ensure that user data is accessed appropriately, by the correct actors.
Example Use Cases
Here are a few examples illustrating how different permission levels can be enforced to restrict access to sensitive data.
Example 1: E-commerce platform with multiple online stores
Imagine you own a large e-commerce platform (we will refer to this as the "parent" organization) which hosts independent user-facing online stores ("child" organizations) selling different items (one for fashion, one for home wares, and so on). Your want your customers to be able to easily move from one online store to another without re-authenticating, and shipping information must be stored securely and shared across stores to reduce friction at checkout. However, there is also store-specific information, such as the items in a basket, which should not be shared across stores.
You can easily achieve all of the above with SlashID, as described below.

First, each child organization should be created to use the same "person pool". This means that the same person registering with multiple child organizations has a consistent person ID across all of them (as long as they use the same email address/phone number to register with each). In this way, the merchants have a consistent identity for authentication.
Second, for each person, the platform wants to be able to securely store shipping information, and have it available to all merchants. This is where attribute buckets come in. Each attribute bucket has a "sharing scope" indicating whether the attributes it contains are for a single organization only, or whether they are available to all organizations sharing a person pool. In this example, the e-commerce platform would use the latter type to store shipping information for each person - meaning all the merchants would be able to access it and pre-fill it for an authenticated user at checkout. Note that this only applies if the person has registered with the merchant - if not, the merchant cannot access that person's attributes, even if they are registered with another organization sharing the pool.
Lastly, there are merchant-specific attributes to store. In this case, an attribute bucket with "organization" sharing scope could be used - meaning only the organization that created the bucket has access to the attributes it contains. Each merchant could use its own bucket to store data for each person, without it being visible to or modifiable by other merchants.
Example 2: Privileged Users
Suppose you have a dashboard available to members of your organization, used to manage aspects of your business. This dashboard can be used to view information, as well as take certain actions (for example, creating or deleting new client accounts). However, not all members of your organization should be able to take actions - only certain privileged users. In this case, you need to be able to authenticate users, and ascertain what actions they can take (if any). However, you also want to make sure that privileges cannot be upgraded by modifying requests from the frontend, and that changes to this user privileges can only be made by trusted admins using back-office APIs.
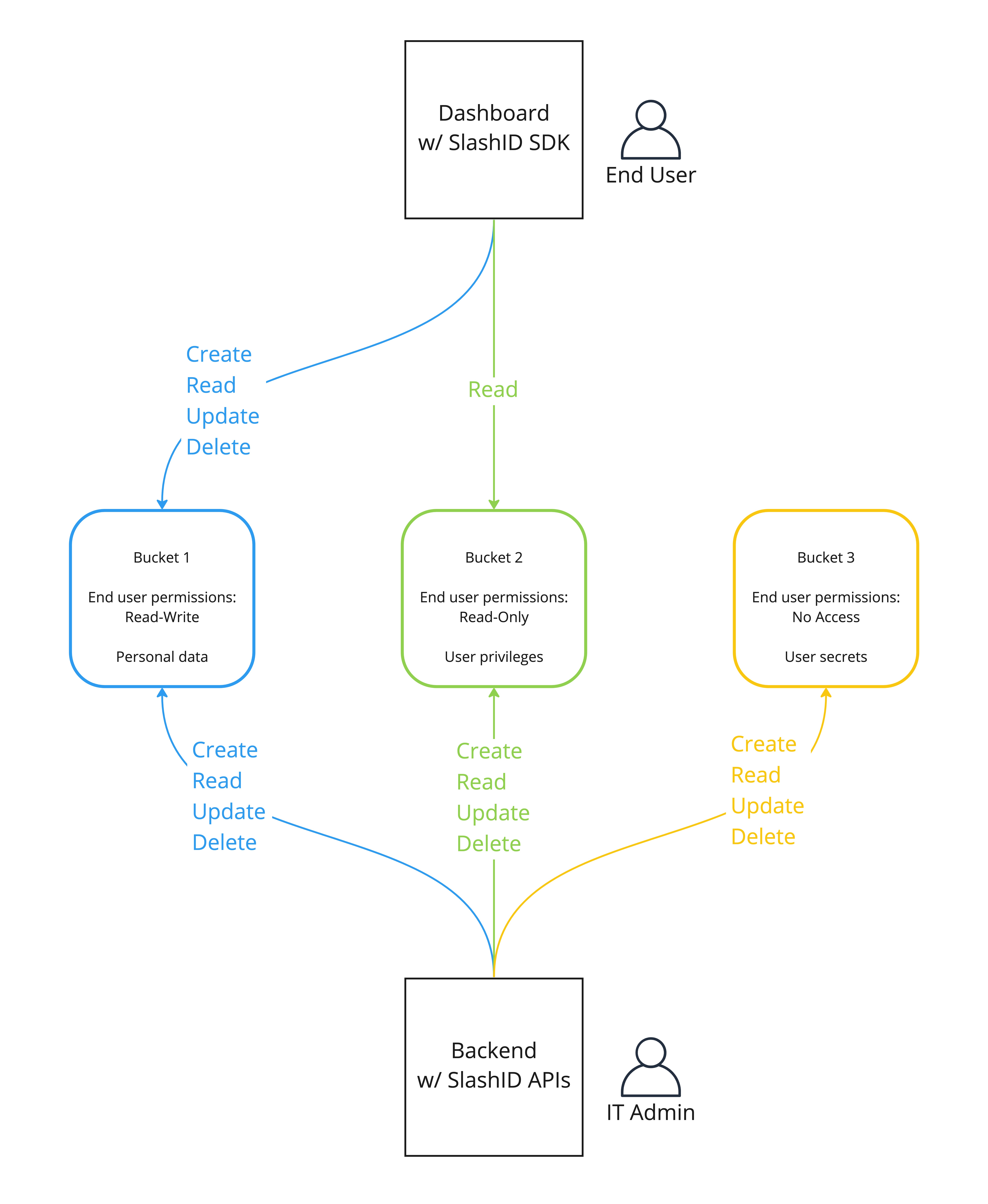
Attribute buckets are ideal for this situation, using the SlashID Javascript SDK or React SDK in your dashboard frontend. First, you can use SlashID Access to authenticate users accessing your dashboard. New users can be created using our APIs, authorized with an API key, and at point of creation an attribute can be assigned indicating their privilege level. This attribute should be readable by the frontend, via the SlashID SDK, but not modifiable. To achieve this, you can use an attribute bucket with the correct end user permissions. These permissions describe the access level an end-user (usually via the SDK) has to the attributes in the bucket: read-write, read-only, or no access. In this case, a bucket with read-only end user permissions would be ideal - this means the SDK can read that attribute (authorized with a user token), but it can only be modified with the back-office APIs, authorized with an API key.
The other permission levels could also be useful. For example, the dashboard might allow users to modify their personal details - in this case, read-write permission would be appropriate. On the other hand, there might be some secret information that should be never be exposed to the SDK - so no access would be correct.
Attribute Access Control with Buckets
All attributes exist in exactly one attribute bucket. The attribute bucket determines who can access the attributes it contains and what actions they can take based on two levels of access control.
Sharing Scope
Organizations can share a person pool, meaning that if the same person registers with multiple organizations in the pool using the same handle, all organizations will see the same person ID. The "sharing scope" of an attribute bucket determines which organizations can access the attributes in the bucket. Sharing scope has two possible values:
- "organization" - just one organization has access to the attributes in the bucket; this organization is the "owner" of the bucket
- "person pool" - all organizations in the pool have access to the attributes in the bucket
Note that in the latter case, a person must be a member of an organization for that organization to access their attributes - even if they are a member of another organization in the same pool, and the attributes are in a person pool-scoped bucket.
End User Permissions
The end user permissions on an attribute bucket determine what actions (if any) an end user can take on attributes in the bucket. An end user can be thought of as a physical person accessing SlashID via a frontend that uses the SlashID SDK; as such the calls are authorized with a user token (as opposed to an API key).
There are three permission levels:
- read-write
- read-only
- no access
In all cases, the SlashID API, authorized with an API key, can be used to take any action on any attribute, as long as the sharing scope of the bucket allows it.
Default Buckets
When an organization is created, SlashID automatically creates six buckets for that organization to use, representing the 2x3 combinations of sharing scope and end user permissions:
- organization-scoped; end user read write
- organization-scoped; end user read only
- organization-scoped; end user no access
- person pool-scoped; end user read write
- person pool-scoped; end user read only
- person pool-scoped; end user no access
If a new suborganization shares a pool with an existing organization, the latter three are not created, as they will already exist and be accessible to the new suborganization.
Currently, we do not expose APIs to create, delete, or modify buckets.
Usage
Listing Buckets
SlashID exposes an endpoint for listing attribute buckets available to your organization:
curl --location --request GET 'https://api.slashid.com/organizations/attribute-buckets' \
--header 'SlashID-OrgID: <ORGANIZATION ID>' \
--header 'SlashID-API-Key: <API KEY>'
The response would be:
{
"result": [
{
"end_user_permissions": "no_access",
"name": "end_user_no_access",
"owner_organization_id": "<ORGANIZATION ID>",
"sharing_scope": "organization"
},
{
"end_user_permissions": "read_only",
"name": "end_user_read_only",
"owner_organization_id": "<ORGANIZATION ID>",
"sharing_scope": "organization"
},
{
"end_user_permissions": "read_write",
"name": "end_user_read_write",
"owner_organization_id": "<ORGANIZATION ID>",
"sharing_scope": "organization"
},
{
"end_user_permissions": "no_access",
"name": "person_pool-end_user_no_access",
"sharing_scope": "person_pool"
},
{
"end_user_permissions": "read_only",
"name": "person_pool-end_user_read_only",
"sharing_scope": "person_pool"
},
{
"end_user_permissions": "read_write",
"name": "person_pool-end_user_read_write",
"sharing_scope": "person_pool"
}
]
}
These are the six buckets created with the organization. All of these can be used immediately by your organization, identified by name, as described below.
Using Buckets
Buckets are identified by their name. Since all attributes belong to a bucket, the bucket must always be specified when reading, writing, or deleting attributes. In some cases, multiple buckets may be specified at once.
With the SDK
Attributes can be created, modified, retrieved, and deleted using the Bucket class
in the Javascript SDK. This provides an interface to manage the attributes in a single bucket for a person.
A Bucket instance can be created using the getBucket method of the User class. If the bucket name
is specified, operations take place on the named bucket; otherwise the default bucket end_user_read_write
is used - this is the organization-scoped bucket with read-write permissions for end-users.
The Bucket class provides three methods for managing attributes:
set, get, and delete. If the bucket does not exist, or the bucket's access control policies
are such that the request is not allowed, the call will return an error.
For example, the following will all return an error:
- the bucket does not exist for your organization (that is, it is not returned in the list of available buckets);
- you call
setordeleteon a bucket withread_onlyend user permissions; - you call
geton a bucket withno_accessend user permissions.
For full reference and examples on using the Javascript SDK to manage attributes, please see the SDK documentation.
With the API
There are two endpoints for managing attributes using APIs.
The /persons/{person_id}/attributes endpoint can be used to
put and
get attributes
in multiple buckets with a single API call. For example:
curl --location --request PUT 'https://api.slashid.com/persons/<PERSON ID>/attributes' \
--header 'SlashID-OrgID: <ORGANIZATION ID>' \
--header 'SlashID-API-Key: <API KEY>' \
--header 'Content-Type: application/json' \
--data-raw '{
"end_user_read_write": {
"address_line_1": "1 Long Street",
"city": "Townville",
"zip_code": "12345"
},
"person_pool-end_user_no_access": {
"secret": "secret-value"
}
}'
Attributes can be retrieved from all buckets:
curl --location --request GET 'https://api.slashid.com/persons/<PERSON ID>/attributes' \
--header 'SlashID-OrgID: <ORGANIZATION ID>' \
--header 'SlashID-API-Key: <API KEY>'
{
"result": {
"end_user_read_write": {
"attr_1": "val_1"
},
"end_user_no_access": {
"secret": "secret-value"
},
"person_pool-end_user_read_write": {
"address_line_1": "1 Long Street",
"city": "Townville",
"zip_code": "12345"
}
}
}
or selected buckets:
curl --location --request GET 'https://api.slashid.com/persons/<PERSON ID>/attributes?buckets=end_user_no_access,person_pool-end_user_read_write' \
--header 'SlashID-OrgID: <ORGANIZATION ID>' \
--header 'SlashID-API-Key: <API KEY>'
{
"result": {
"end_user_no_access": {
"secret": "secret-value"
},
"person_pool-end_user_read_write": {
"address_line_1": "1 Long Street",
"city": "Townville",
"zip_code": "12345"
}
}
}
Alternatively, the /persons/{person_id}/attributes/{bucket_name} endpoint can be
used to get,
put,
and delete
attributes in a specific bucket.
For example, to put attributes:
curl --location --request PUT 'https://api.slashid.com/persons/<PERSON ID>/attributes/end_user_no_access' \
--header 'SlashID-OrgID: <ORGANIZATION ID>' \
--header 'SlashID-API-Key: <API KEY>' \
--header 'Content-Type: application/json' \
--data-raw '{
"client_secret": "4847ab44d8700ab3"
}'
To get, either all the attributes in the bucket can be retrieved:
curl --location --request GET 'https://api.slashid.com/persons/<PERSON ID>/attributes/end_user_no_access' \
--header 'SlashID-OrgID: <ORGANIZATION ID>' \
--header 'SlashID-API-Key: <API KEY>'
{
"result": {
"client_secret": "4847ab44d8700ab3",
"secret": "secret-value"
}
}
or named attributes:
curl --location --request GET 'https://api.slashid.com/persons/<PERSON ID>/attributes/end_user_no_access?attributes=client_secret' \
--header 'SlashID-OrgID: <ORGANIZATION ID>' \
--header 'SlashID-API-Key: <API KEY>'
{
"result": {
"client_secret": "4847ab44d8700ab3"
}
}
Deleting works in the same way as get, so attribute names can be specified; if none are specified, all attributes in the bucket are deleted.