App-layer cryptographic primitives for secure storage of user data
Background
Since SlashID’s inception, our goal has been to give developers a secure way to store user data without hosting it on their own internal infrastructure or worrying about how to do cryptography right.
Furthermore, the regulatory environment around user data was becoming increasingly strict, so we aimed to build a data storage engine that was not only safe but also complied by design with data protection and localization regulations mandated by various jurisdictions.
Given our premises, we had a number of requirements for our data encryption layer:
- Database-agnostic
- Serverless
- Handles encryption and data localization transparently
- Hardware-based root of trust to implement crypto-anchoring and avoid mass data exfiltration
- Data can be either globally replicated or localized to an individual region
- Compliance with GDPR and similar regulations by (i) keeping an audit log of data access requests and (ii) using crypto-shredding to service data deletion requests
- No noticeable latency for the end user
- Ability to perform encrypted searches with equality
In the following sections we’ll describe the architecture of our storage encryption layer and the primitives used to build it.
A better Developer Experience
We are engineers first and foremost and it was important for us to build a product developers genuinely want to use because it simplifies their day to day job. In the context of authentication and identity management, this translates into building a platform that allows developers to stop spending cycles to implement and worry about encryption, data localization or key management and rotation.
From the outside, SlashID’s interface looks like a standard REST API, coupled with a set of SDKs, both client-side and server-side, that together allow developers to store and retrieve users and their associated data.
For instance, this is a code snippet that shows how to register/sign-in an user and how to store and retrieve encrypted attributes using our client-side JavaScript SDK:
var sid = new slashid.SlashID()
…
const user = await sid.id(
Organization_ID,
{
type: "phone_number",
value: "+13337777777"
},
{
method: "webauthn"
}
)
…
await user.set({"attr1": "value1"})
const attrs = await user.get()
// => attrs === {"attr1": "value1", …}
In the example above, we are registering/logging in a user by the phone number +13337777777 as handle, and using webauthn as the authentication method. By default, if the user connected to the website from Lisbon their data would be automatically stored in the EU, if they connected from New York the data would be stored in the US - you can override that choice in the id() call.
Calling set on a user creates a new attribute in our Data Vault module. When that happens an attribute-specific key is generated and is used to encrypt value1. The key is itself encrypted with a user-specific key generated at user-creation time.
Calling get on a user allows you to retrieve one or more attributes associated with the user. The attributes are decrypted and returned in clear-text to the caller.
Note how, throughout the example, you don't have to worry about encryption nor data localization and the user data never touches your own infrastructure.
Overall architecture
We made the decision that our encryption layer would be database-agnostic. This was done because we want the possibility to expand datastore coverage beyond our current database if needed.
Some data structures in our architecture are encrypted and globally replicated while others are encrypted but localized to a specific region.
We make extensive use of envelope encryption. Our chain of trust forms a tree as depicted below, each child key is encrypted with the parent key.
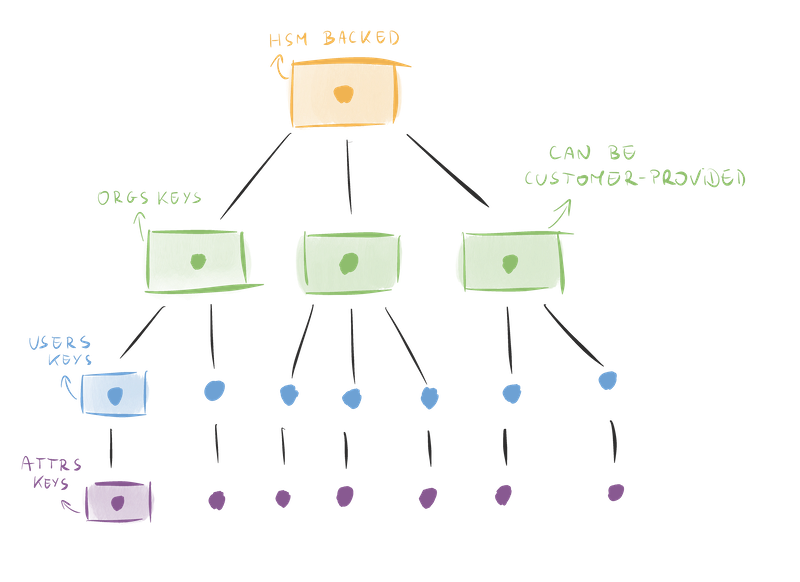
Properties of the key hierarchy
The key hierarchy mentioned above is generated per-region and this structure brings a number of advantages:
- A compromised key doesn’t compromise all the data
- Deleting user data can be achieved through crypto-shredding by deleting the corresponding user key
- Data can be replicated globally without violating data residency requirements since the keys are localized per-region
- The root of trust is stored in a Hardware Security Module (HSM) making a whole-DB compromise an extremely arduous task
- We can enforce fine-grained access control on the HSM to tightly control and reduce the number of services able to decrypt subtrees
Keys lifecycle
Keys are created on demand when a new org, a new user or a new attribute is generated. Keys are never stored unencrypted anywhere at rest and only one service within SlashID’s infrastructure has the ability to access the HSM to decrypt the master key, significantly reducing the chances of compromise.
Derived keys are stored in a database that is encrypted, geo-localized and backed-up every 24 hours.
Lastly, all keys are rotated at regular, configurable, intervals.
The primitives
We spent a significant amount of time evaluating the correct set of primitives to use for our architecture. Below are some of the key decisions we made.
HSM selection
At this point, we don’t have a dedicated data center at SlashID, so we evaluated various solutions provided by external cloud vendors.
We excluded Azure right away because it doesn’t support symmetric keys unless using managed HSMs. Azure is also not supported by our cryptographic library of choice, Tink.
There’s minimal difference in features or cost between GCP and AWS, but we ended up picking GCP because of two key features:
- GCP’s External Key Manager (EKM) supports the use of external HSM vendors out of the box, allowing our customers to pick an HSM vendor of their choice and to manage their own keys.
- GCP is certified FIPS 140-2 Level 3, whereas AWS is FIPS 140-2 Level 2, hence GCP has stronger security guarantees.
Cryptographic library
When implementing any cryptographic system, selecting the correct library is paramount. Our library of choice is Google Tink. This presentation does a great job of explaining Tink’s design principles and why it’s a superior choice when compared to better known libraries such as OpenSSL.
For our Data Vault module, we were looking for a few key features:
- Support for deterministic authenticated encryption
- Native Golang support since that’s the primary language our backend is written in
Tink also has a few more unique features:
- Tink manages nonces directly, preventing mistakes in the implementation or usage of cryptographic algorithms, which could easily result in vulnerabilities
- Tink has an interface to talk directly to HSMs hosted in GCP and AWS, reducing the burden of managing the KMS/Cloud HSM APIs
- Tink reduces key rotation complexity through keysets
While Tink is not the fastest cryptographic library available today, it is the easiest to use safely and, as we’ll see below, the performance overhead is still negligible for the algorithms we adopt.
Key Types and Encryption Modes
We employ a variety of encryption methods depending on the data type. Tink provides a long list of supported types.
At a high level, we employ deterministic encryption for data on which we perform encrypted search. For most of the remaining data, we use AES-GCM encryption, which has hardware support on most modern processors and generally faster performance without sacrificing security. If you want to read more, this blogpost does a great job at comparing symmetric encryption methods.
Note that, strictly speaking, AES-GCM-SIV and XChaCha20-Poly1305 would be safer choices because they either have longer nonces or prevent nonce abuse. However, AES-GCM-SIV comes with a ~30% performance hit, which we considered unacceptable for our use case, and, as mentioned earlier, Tink also implements safe nonce management.
As for XChaCha20-Poly1305, it is cryptographically stronger than GCM because it has a longer nonce. However, its performance is worse compared to AES-GCM due to the lack of built-in hardware instruction sets. We overcome that risk by not reusing keys and by letting Tink handle nonce management.
Secure enclaves or not?
Both AWS and GCP provide support for confidential computing. In AWS, trusted environments go under the commercial name of Nitro Enclaves, whereas in GCP they are called Confidential VMs.
The principle behind both products is to provide an isolated environment similar to what HSMs provide, but using Virtual Machines instead of hardware.
Ultimately, we decided against using Confidential VMs or Nitro Enclaves due to the very limited security benefits they provide. To understand why, let’s analyze Nitro Enclaves briefly; very similar considerations apply to GCP’s Confidential VMs.
Nitro Enclaves are implemented by partitioning the CPU and memory of a single “parent” EC2 instance to run a Docker container in them. While a container can normally perform arbitrary computation, when executed within a Nitro Enclave its only external communication channel is a single socket connection via Virtual Sockets, while the Enclave runs a nested, secure, hypervisor. From the outside, you can't see any internal console messages, logs or access the container in any way. The only visible data is the input and output of the sockets. Further, only the parent instance (i.e.,the EC2 that created the enclave), can communicate with the Docker container running inside the enclave.
The enclave created in this way has two key features:
- The enclave can speak directly to AWS’ Key Manager Service (KMS) over TLS. Hence, data encryption/decryption can be achieved directly from the Docker container inside the Nitro Enclave without talking to the parent instance.
- The enclave generates an attestation of the Docker container running on it. This attestation allows you to create access rules within the KMS, so that only enclaves with a particular hash (i.e., a specific pre-agreed Docker image, running pre-agreed code) can decrypt data.
While these two properties have high value, lambda functions within GCP and AWS provide similar isolation features and significantly lower lifetime, reducing the burden and risk of maintaining an EC2 instance.
We evaluated whether the benefits of KMS Key Policy attestation were valuable enough to justify the extra overhead, and, in the end, determined that it was not a favorable tradeoff. This is primarily because KMS policies are governed by IAM roles in AWS, so they are not a silver bullet in and of themselves: an attacker with access to IAM can change the KMS policies and swiftly invalidate any advantage of Nitro Enclaves with respect to access control.
So while Nitro Enclaves offer marginally more protections than standard instances, we think that that protection is offset by the additional complexity and the longer lifespan of the EC2 instance running the enclave.
In the end, for our use case, an adequate IAM policy coupled with serverless execution provides a strong and comparable safe alternative.
Performance impact
As we already discussed, algorithm selection was a key consideration for us, both in terms of security and speed. To test the impact of encryption on performance, we ran our service with and without encryption.
Our benchmarks indicate that the overhead of our encryption layer vs clear-text for data retrieval is as follows:
BenchmarkDecryptAttributes_1b-10 65793 17894 ns/op 9440 B/op 146 allocs/op
BenchmarkDecryptAttributes_4b-10 72162 18019 ns/op 9456 B/op 146 allocs/op
BenchmarkDecryptAttributes_64b-10 68924 17904 ns/op 9696 B/op 146 allocs/op
BenchmarkDecryptAttributes_1024b-10 59560 20180 ns/op 13536 B/op 146 allocs/op
BenchmarkDecryptAttributes_4096b-10 48620 24793 ns/op 25824 B/op 146 allocs/op
BenchmarkDecryptAttributes_65536b-10 13249 89876 ns/op 263393 B/op 146 allocs/op
We believe that ~0.08 milliseconds for a 64k block is an acceptable result for our needs and the sub-linear growth in latency means that we would be able to process even significantly larger attributes with minimal performance impact.
Threat model
When we built Data Vault, our aim was to create an exfiltration-resistant, fast and compliant module for our customers.
The threat we care the most about is an attacker compromising our infrastructure and exfiltrating customer data in bulk. Our security posture is an evolution of the setup described a few years ago by Diogo Monica and Nathan McCauley from Anchorage and Square in this blog post.
In our system, data exfiltration attacks are prevented thanks to three design choices:
- The root of trust is an HSM and only a single service is able to talk to it
- Each attribute and each user are encrypted with a separate, individual key, and therefore the loss of a key doesn’t result in loss of other data
- We use encryption search to minimize the encryption/decryption operations performed in our environment, reducing the exposure of keys
While our architecture doesn’t entirely rule out the risk of mass-exfiltration, it reduces the attack scenarios to one of two cases:
- The attacker is able to compromise the service allowed to speak with the HSM by obtaining full code execution, and exploit that to decrypt the org keys
- The attacker has compromised our IAM system and has diverted HSM access to a third-party service that is attacker-controlled
We employ a number of additional countermeasures to further reduce the two risks above. These measures are probabilistic in nature and hence we prefer not to discuss them publicly.
Comparing Data Vault with the standard database encryption options makes it clear how Data Vault is significantly more secure than other storage alternatives. In fact, in a traditional environment, obtaining access to the database is all the attacker needs in order to exfiltrate or alter customer data – a significantly easier attack path.
Disaster recovery
Given our security posture, it is key to prevent accidental deletion of encryption keys. We maintain a robust disaster recovery posture through the following steps:
- HSM keys are only scheduled for destruction with a 90 days grace period.
- Derived keys are stored and encrypted in a database that is replicated and backed up every 24 hours
End-to-End Encryption
Our current threat model protects user data from malicious third-parties but doesn’t prevent the organization the user belongs to or SlashID from accessing the data.
Sometimes, it is desirable for the user to have data that can only be accessed by the user and no other third parties, including SlashID. For instance, Flo is offering anonymous mode to users who don’t want to share their information after the Roe vs. Wade ruling.
In a separate article we’ll describe our approach to E2E Encryption of user attributes and how our customers can leverage it to provide stronger security guarantees to their users.