Data Protection and Privacy Laws: Requirements and SlashID capabilities
This is not legal advice, you should consult your counsel and Data Protection Officer to understand specific requirements your business might be subject to with respect to data protection, residency and privacy laws and regulations.
While SlashID can help reduce the technical and engineering burden it does not relieve your company from the legal responsibilities imposed by the regulatory frameworks your company might be subject to.
In recent years regulation around personal data broadly defined has increased significantly. While different countries, industries and companies are subject to different requirements there are some broad tenets around data encryption, residency and consent that are shared across more regulatory frameworks.
SlashID was built from Day 1 for multi-region and multi-tenancy with security and compliance in mind.
In particular, we provide five key components to help with compliance:
User-level data residency: All user data is by default stored in the region geographically closest to the user automatically and transparently without having to create separate regional tenants. Additionally, we globally replicate some user data in hashed form to ensure fast data retrieval, while remaining compliant and secure.
App-layer, per user, data encryption: Each user record and attributes are encrypted with a dedicated key at the app-level with a regional HSM as the root of trust. This provides data-exfiltration guarantees and complies with the strictest data residency laws.
Crypto-shredding for data erasure: Thanks to our app-layer encryption posture we can service right to be forgotten request easily and compliantly by employing crypto-shredding. Each deletion generates an audit trail that can be imported in your log collection solution of choice.
APIs for consent collection: We expose APIs to collect and track user consent in accordance to several regulatory frameworks.
Client-side accessible data buckets: User data can be stored in client-side accessible attributes buckets to help fullfil data access rights requests.
Note that our data residency and encryption capabilities in Data Vault are available to customers irrespective of the adoption of the authentication features.
Data Residency
You can find the technical details on our approach here.
Our API and SDKs further support specifying a region for queries such that a user is created in a specific region or that only a specific region is queried when retrieving the user data.
The user can either be created directly from the front-end through our access SDK or in the backend through our APIs. In the latter case, an example call looks as follows:
curl -L -X POST 'https://api.sandbox.slashid.com/persons' \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-H 'SlashID-API-Key: <API_KEY_VALUE>' \
--data-raw '{
"active": true,
"roles": [
"['\''admin'\'', '\''user'\'']"
],
"attributes": "{ \"person_pool-end_user_read_write\": { \"card_number\": \"1234\", \"expiry\": \"07/25\" }, \"organization-end_user_read_only\": { \"address_line_1\": \"New Street\" , \"city\": \"New York\" } }",
"handles": [
{
"type": "email_address",
"value": "user@user.com"
}
],
"groups": [
"string"
],
"region": "us-iowa"
}'
Notice how we had to specify a region parameter in the request. It's important to note that contrary to other solutions that require the manual creation and configuration of separate tenants per region, the user is not segregated in a separate organization or tenant per region in SlashID. This allows sharing of organizations-wide roles, rules, and analytics without any manual duplication work.
Further, if using Identity Management and Data Vault, SlashID replication posture provides two further key benefits:
- Performance: if a user is accessing your application from a location physically distant from where the data is stored, each request will be slower.
- Availability: if you are using a single region, you have a single point of failure - if the region is down, your application is down.
When it comes to retrieving user data, our API supports retrieval per region to avoid accidentally accessing cross-region data.
Data Encryption
A detailed explanation of our encryption posture is here.
We made the decision that our encryption layer would be database-agnostic. This was done because we want the possibility to expand datastore coverage beyond our current database if needed.
Some data structures in our architecture are encrypted and globally replicated while others are encrypted but localized to a specific region.
We make extensive use of envelope encryption. Our chain of trust forms a tree as depicted below, each child key is encrypted with the parent key.
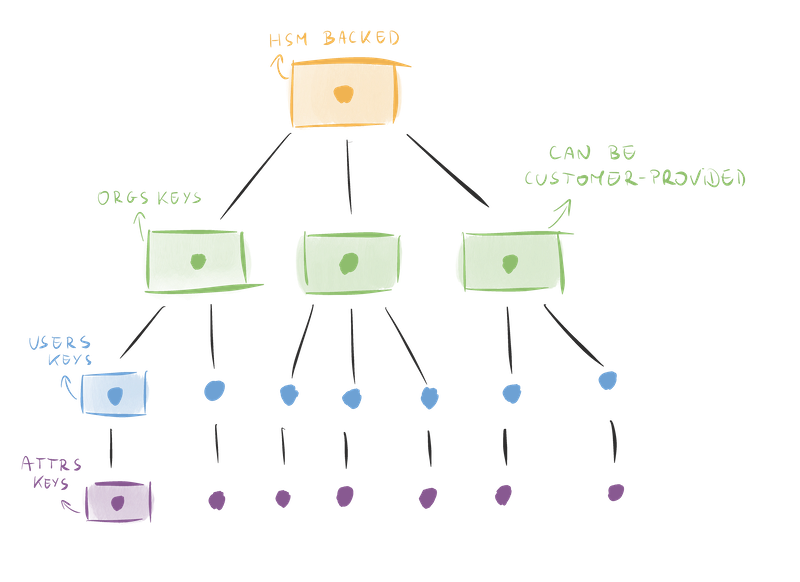
In our system, data exfiltration attacks are prevented thanks to three design choices:
- The root of trust is an HSM and only a single service is able to talk to it
- Each attribute and each user are encrypted with a separate, individual key, and therefore the loss of a key doesn’t result in the loss of other data
- We use encryption search to minimize the encryption/decryption operations performed in our environment, reducing the exposure of keys
While our architecture doesn’t entirely rule out the risk of mass-exfiltration, it reduces the attack scenarios to one of two cases:
- The attacker is able to compromise the service allowed to speak with the HSM by obtaining full code execution, and exploit that to decrypt the org keys
- The attacker has compromised our IAM system and has diverted HSM access to a third-party service that is attacker-controlled
Crypto Shredding
The delete person API automatically shreds the user key that is the root key for all user attributes. This guarantees that no user PII is accessible through SlashID once the user has been deleted.
Consent API
SlashID exposes an API to record consent that can be employed to comply with the Right to Object as described in the GDPR regulation and we are constantly expanding the set of supported regulatory frameworks.
The API is accessible both client-side and server-side and provides a tamper-proof log of consent tracking and changes.
Attribute buckets
User data is represented and stored as key-value pairs, which can be retrieved and used at any point in time. However, not all user data is equal, and you may often want to control who is able to access and modify specific data. By defining permissions at the bucket level, you can easily ensure that user data is accessed appropriately, by the correct actors.
The technical details about our attributes buckets are available here.